

Le Fine-Tuning a pendant longtemps été une méthode redoutablement efficace pour adapter les modèles de langage (LLM) à une tâche spécifique.
Est-il encore utile aujourd’hui ?
Découvrez les méthodes d’apprentissage des modèles de langage, le fonctionnement du Fine-Tuning, ses applications, et pourquoi il n’est quasiment plus nécessaire pour la plupart des applications.
Qu’est-ce que le Fine-Tuning ?
Les LLM sont des modèles de langages génériques, qui à partir de leur représentation des textes donnés en entrées, peuvent exécuter une grande variété de tâches telles que génération de texte, résumé, classification, traduction, etc.
Le Fine-Tuning est une technique utilisée dans le domaine du traitement du langage naturel (NLP) qui consiste à adapter un modèle de langage à une tâche spécifique en utilisant des données d’apprentissage spécifiques de la tâche.
L’idée est de partir des connaissances générales acquises par le modèle lors de son entraînement initial sur de vastes corpus de textes, et de les affiner pour une application particulière.
Cependant, avec l’évolution rapide des modèles de langage et l’émergence de nouvelles approches comme le prompt engineering, la pertinence du Fine-Tuning est remise en question.
Étapes d’apprentissage des LLM
Pour bien comprendre le rôle du Fine-Tuning, il est essentiel de revenir sur les étapes de l’apprentissage des modèles de langage modernes.
Entraînement initial
Le modèle est entraîné sur de très grands volumes de données textuelles non étiquetées, souvent extraites du web. Cet entraînement non supervisé permet au modèle d’apprendre des structures linguistiques et des relations sémantiques entre des mots et des phrases.
Reinforcement Learning
Le modèle de langage entre ensuite en phase d’apprentissage par renforcement (Reinforcement Learning) où il apprend à partir des nouvelles données qui lui sont soumises. De plus, grâce à une architecture de type Transformer, les LLM peuvent traiter de longues séquences de texte et retenir des informations contextuelles sur plusieurs tours de conversation avec les utilisateurs. Autant de données qui alimentent un apprentissage continu.
Dans le cadre d’un usage en entreprise, le Reinforcement Learning signifie ni plus ni moins que le modèle incorpore les documents qu’on lui soumet. Attention aux données sensibles ou confidentielles, d’autant plus lorsque vous utilisez des outils d’IA générative grand public.
Pourquoi utiliser le Fine-Tuning de LLM ?
En 2018, à l’époque de BERT, le Fine-Tuning était la méthode incontournable pour adapter un modèle à des tâches spécifiques. Le Fine-Tuning permettait d’ajouter ou de modifier des paramètres aux modèles après leur entraînement initial pour améliorer leurs performances sur des tâches particulières.
Aujourd’hui, la donne a changé. Avec la rapide évolution des technologies d’intelligence artificielle et les méthodes de Reinforcement Learning, les capacités des LLM ont évolué au point où le prompt engineering permet d’obtenir des résultats comparables, voire supérieurs, sans recourir au Fine-Tuning.
Bien que le Fine-Tuning puisse parfois être efficace en termes de temps et de ressources de calcul, les coûts associés sont considérables. Et compte tenu de la vitesse à laquelle évoluent les LLM, il n’est pas certain que le Fine-Tuning soit financièrement viable à court ou moyen terme.
Comment réaliser le Fine-Tuning d’un LLM ?
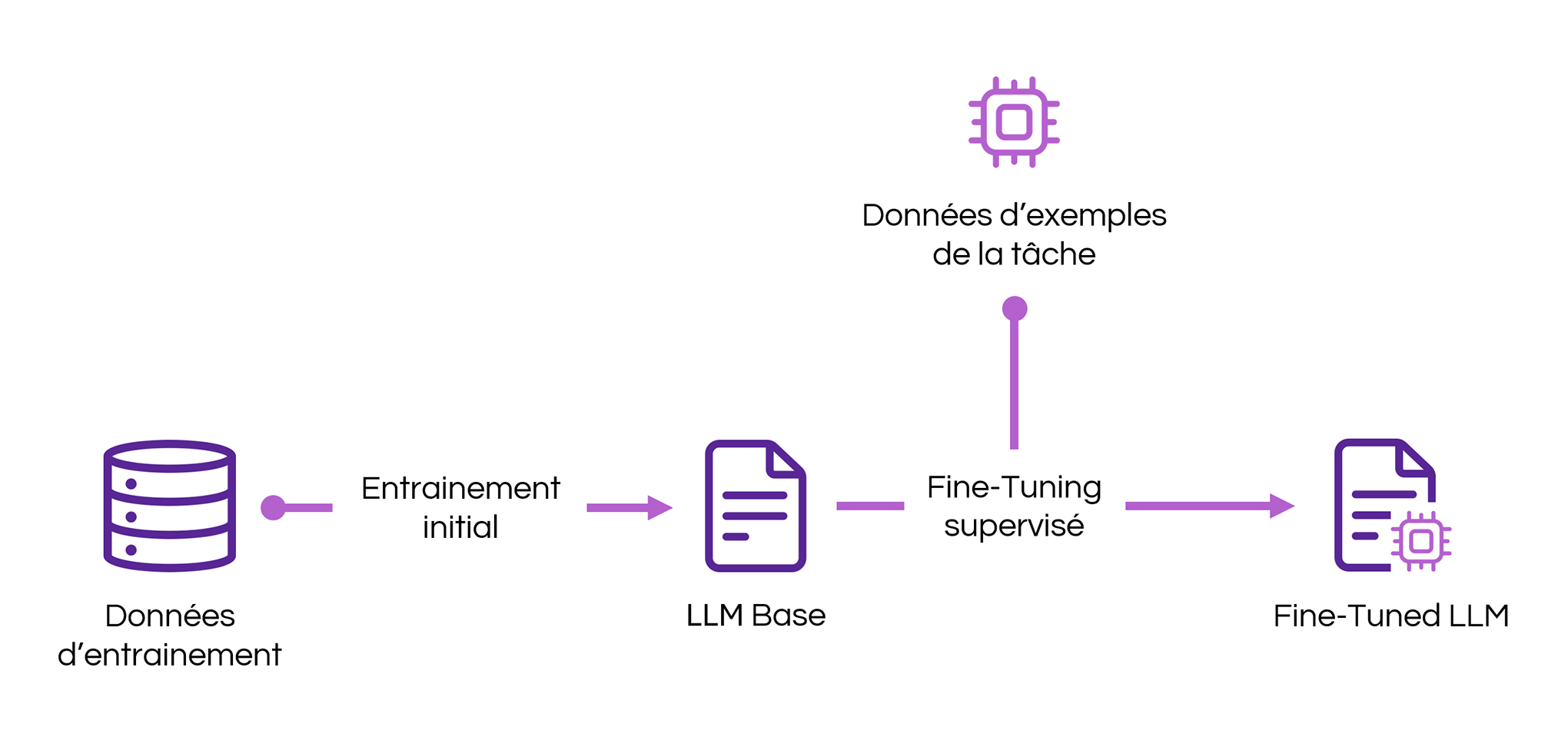


D’un point de vue technique, le Fine-Tuning d’un modèle de langage peut être réalisé de plusieurs façons.
Méthode 1 : Full Fine-Tuning
Le Full Fine-Tuning consiste à ajuster l’ensemble des paramètres du réseau de neurones. Cette méthode est la plus complète mais nécessite des ressources de calcul importantes.
Méthode 2 : Parameter Efficient Fine-Tuning (PEFT)
Le PEFT implique de ne mettre à jour qu’une partie des couches du modèle, les autres étant « gelées » (leurs paramètres restent fixes). Cette méthode réduit les besoins en calcul tout en adaptant efficacement le modèle.
Méthode 3 : Adapters
Les Adapters sont des modules complémentaires ajoutés au LLM original. Ils contiennent beaucoup moins de paramètres que le modèle complet, ce qui permet de le spécialiser sans modifier la structure de base (les paramètres sont « gelés »). C’est une option intéressante lorsqu’on souhaite utiliser le même modèle pour de multiples tâches, en changeant simplement d’Adapter.
Mise à jour des paramètres
Quelle que soit la méthode choisie, le Fine-Tuning s’appuie généralement sur des techniques d’apprentissage supervisé afin d’ajuster les paramètres, en utilisant des données étiquetées pour la tâche cible.
Défis et limites
Si le Fine-Tuning a longtemps été un passage obligé pour tirer parti des modèles de langage pré-entraînés, il présente aussi plusieurs défis et limites.
Sur-apprentissage
Le Fine-Tuning présente un risque de sur-apprentissage (overfitting) sur les données spécifiques utilisées. Le modèle peut devenir trop spécialisé et perdre sa capacité à généraliser sur d’autres types de données.
Qualité des données
Le Fine-Tuning nécessite des données de qualité et représentatives pour être efficace. Si les données sont de mauvaise qualité (garbage in), les performances du modèle seront compromises (garbage out).
Performances
Le Fine-Tuning peut entraîner une dégradation des performances sur les tâches d’origine, un phénomène connu sous le nom de « catastrophic forgetting ». Le modèle peut oublier les connaissances acquises pendant l’entraînement initial en se concentrant trop sur la nouvelle tâche.
Prompt Engineering
Le prompt engineering offre une alternative plus simple et souvent plus efficace. En concevant des instructions claires et précises, on peut obtenir des résultats de haute qualité sans recourir au Fine-Tuning.
Pour en savoir plus, découvrez des techniques de prompt engineering et des prompt frameworks adaptés à votre usage professionnel.
Exemples d’applications
Cas d’usages historiques
L’analyse de sentiments sur des avis de produits, où le modèle est entraîné à distinguer les opinions positives et négatives à partir d’un corpus d’avis étiquetés.
La classification de textes pour la détection de spams dans les emails, où le modèle apprend à différencier les messages légitimes des messages indésirables.
La reconnaissance d’entités nommées dans des documents légaux, où le modèle est spécialisé pour repérer et catégoriser les noms de personnes, d’organisations, de lieux, etc.
La traduction automatique pour un domaine spécifique, comme la traduction de documents médicaux, où le modèle est adapté au vocabulaire et aux tournures propres au domaine.
Cas d’usages actuels
Aujourd’hui, le prompt engineering rend le Fine-Tuning obsolète dans de nombreux cas. En utilisant des prompts bien conçus, les modèles de langage peuvent accomplir des tâches variées sans nécessiter d’ajustements spécifiques.
Conclusion
Le Fine-Tuning, autrefois essentiel pour adapter les modèles de langage à des tâches spécifiques, devient de plus en plus obsolète. Grâce aux évolutions rapides des LLM et au développement du prompt engineering, il est désormais possible de réaliser des performances comparables sans recourir à l’ajustement des modèles.
Dans tous les cas, essayez dans un premier temps de réaliser vos tâches avec des prompts clairs avant d’envisager le Fine-Tuning.
Si vous avez un cas d’usage concret et récent où le Fine-Tuning d’un LLM est essentiel, contactez-nous. Nous serons heureux d’intégrer votre expérience dans notre blog.



